Summary
* 신경망의 최적화 보조 수단인 두가지를 레이어에 대해서 알아본다.
* 첫번째는 과적합(Overfitting) 완화하는 Dropout
* 두번째는 불안정(Unstable)하거나 느린(Slow) 학습을 보완하는 Batch Normalization
Dropout
신경망 학습 과정에서 가짜 패턴(또는 불필요한 정보) 때문에 과적합(Overfitting)이 발생한다.
이는 훈련 데이터의 패턴이 너무 구체적이기 때문에 취약한 경우가 있다.
과적합(Overfitting)을 완화하기 것이 Dropout 이다.
Dropout은 훈련 단계마다 Layer의 입력 단위 중 일부를 무작위로 삭제한다.
신경망이 훈련 데이터에서 가짜 패턴을 학습하는 것이 어려워진다.
대신, Weight 패턴은 더 강한 경향성을 지닌 광범위하고, General 패턴을 찾아야 한다.

Dropout 일종의 Ensemble of Network 만드는 것과 유사하다.
큰 네트워크에서 개별적으로 판단하고, 이를 모아서 최종 판단을 한다.
개별적으로 실수할 수 있지만, 네트워크 전체가 실수 확률을 낮다는 관점에 아이디어이다.
Adding Dropout
Karas에서는 Dropout rate를 인수로 지정하고, Dropout을 적용할 계층 앞에 배치한다.
keras.Sequential([
# ...
layers.Dropout(rate=0.3), # apply 30% dropout to the next layer
layers.Dense(16),
# ...
])Batch Normalization
Batch Normalization (or bachnorm)는 불안정(unstable)하거나 느린(slow) 학습 과정을 보완하는기능을 가진 Layer이다.
신경망을 사용할 경우, Scikit-learn의 Standard Scalar 또는 MinMax Scalar 와 같은 것을 이용하여 학습 데이터의 스케일 일관적으로 맞추는 것이 좋다. 이유는 SGD(Stochastic Grandient Descent)는 데이터 Activation을 생성되는 크기에 비례하여 네트워크 가중치(Network Weight)를 이동(Shift)하기 때문이다. 편차가 큰 Activation을 생성하는 경향을 지닌 학습 데이터(Feature)는 불안정한 훈련 행동이 발생할 수 있다.
데이터가 신경망에 입력되기 전에 Normalization 하는 것이 좋다면, 신경망 내부에서 Normalization하는 것이 좋다.
Batch Normalization은 신경망에서 이러한 기능을 가진 Layer이다.
Batch Normalization Layer는 입력되는 각 배치를 보고,
먼저, 자체 평균(own mean) 및 표준 편차(standard deviation)를 계산하여 Batch Normalization
그 다음, 두 개의 훈련 가능한 재조정 매개변수( trainable rescaling parameters ) 사용하여 새로운 척도(new scale)로 배치한다.
Batchnorm는 입력(inputs)의 rescaling을 coordination하는 것이다.
[Batchnorm가 필요한 이유]
1) 신경망 최적화 프로세스(Optimization Process)의 보조 수단으로 신경망의 예측 성능(Predction Performance) 향상에 도움이 될 수 있다.
2) 모델 훈련을 완료하는 epoch 수를 줄일 수도 있다.
3) 훈련 과정에서 발생할 수 있는 일부 예외를 해결할 수도 있다.
Adding Batch Normalization
keras에서 신경망의 거의 모든 지점에서 사용될 수 있다.
Layer 뒤에 지정하거나
#...
layers.Dense(16, activation='relu'),
layers.BatchNormalization(),
#...활성화 함수(Activation Function) 앞에 지정하거나
# ...
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),
# ...또는 layers.BatchNormalization()를 네트워크에서 맨 첫번째에 추가하면 Scikit Learn의 Standard Scaler와 같은 기능 대신하는 적응형 전처리기(Adaptive Preprocessor) 역할을 할 수도 있다.
Using Dropout and Batch Normalization
이전 과정에서 만들었던 레드 와인 모델을 계속해서 수정한다.
아래는 데이터 표준화는 제외하고, Batch Normalization 을 통해 훈련을 안정화하는 예제이다.
신경망의 수용성(Capacity) 훨씬 더 늘리고, 과적합 제어를 위한 Dropout 및 최적화 속도 향상시키기 위한 Batch Normalization Layer 를 추가한다.
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(1024, activation='relu', input_shape=[11]),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1),
])(이전 과정에서 사용했던 코드를 그대로 사용한다)
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=100,
verbose=0,
)
# Show the learning curves
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();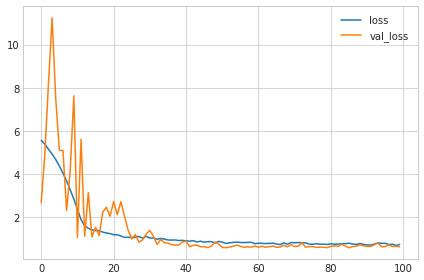
일반적으로 학습하기 전에 데이터를 표준화하면 모델의 성능이 향상된다.
하지만, 여기서는 원시 데이터를 그대로 사용함하여 Batch Normalization이 얼마나 효과적인지 알 수 있다.
Dropout Evaluation
spotify 데이터 불러오기
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('animation', html='html5')
import pandas as pd
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import make_column_transformer
from sklearn.model_selection import GroupShuffleSplit
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import callbacks
spotify = pd.read_csv('./data/spotify.csv')
X = spotify.copy().dropna()
y = X.pop('track_popularity')
artists = X['track_artist']
features_num = ['danceability', 'energy', 'key', 'loudness', 'mode',
'speechiness', 'acousticness', 'instrumentalness',
'liveness', 'valence', 'tempo', 'duration_ms']
features_cat = ['playlist_genre']
preprocessor = make_column_transformer(
(StandardScaler(), features_num),
(OneHotEncoder(), features_cat),
)
def group_split(X, y, group, train_size=0.75):
splitter = GroupShuffleSplit(train_size=train_size)
train, test = next(splitter.split(X, y, groups=group))
return (X.iloc[train], X.iloc[test], y.iloc[train], y.iloc[test])
X_train, X_valid, y_train, y_valid = group_split(X, y, artists)
X_train = preprocessor.fit_transform(X_train)
X_valid = preprocessor.transform(X_valid)
y_train = y_train / 100
y_valid = y_valid / 100
input_shape = [X_train.shape[1]]
print("Input shape: {}".format(input_shape))30% 비율의 dropout 레이어가 설정된 신경망을 생성한다.
model = keras.Sequential([
layers.Dense(128, activation='relu', input_shape=input_shape),
layers.Dropout(rate=0.3),
layers.Dense(64, activation='relu'),
layers.Dropout(rate=0.3),
layers.Dense(1)
])모델 학습하여 Dropout 효과를 확인한다.
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=50,
verbose=0,
)
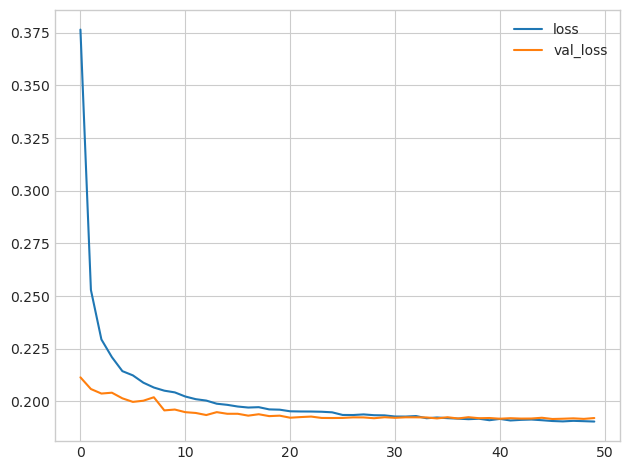
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot()
print("Minimum Validation Loss: {:0.4f}".format(history_df['val_loss'].min()))만약, 신경망에서 Dropout 없이 학습할 경우 아래와 같이 과적합(overfitting)이 발생하는데,
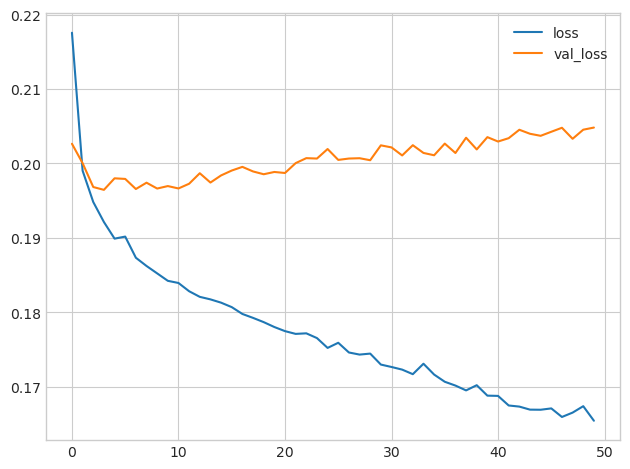
아래 dropout을 포함한 신경망의 학습 곡선을 보면 훈련 손실(loss)이 계속 감소하더라도 유효성 검사 손실(val_loss)이 일정한 최소값에 가깝게 유지됨을 알 수 있다. 이를 통해서 Dropout이 과적합을 방지하는 것을 확인할 수 있다.
Batch Normalization Evaluation
먼저 배치 정규화 효과를 확인하기 위해서 표준화되지 않은(Unstandardized) 콘크리트 데이터셋을 불러온다.
import pandas as pd
concrete = pd.read_csv('./data/concrete.csv')
df = concrete.copy()
df_train = df.sample(frac=0.7, random_state=0)
df_valid = df.drop(df_train.index)
X_train = df_train.drop('CompressiveStrength', axis=1)
X_valid = df_valid.drop('CompressiveStrength', axis=1)
y_train = df_train['CompressiveStrength']
y_valid = df_valid['CompressiveStrength']
input_shape = [X_train.shape[1]]표준화되지 않은 콘크리트 데이터셋으로 모델을 학습한다.
# create model
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=input_shape),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
# compile model
model.compile(
optimizer='sgd', # SGD is more sensitive to differences of scale
loss='mae',
metrics=['mae'],
)
# train model
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=64,
epochs=100,
verbose=0,
)
history_df = pd.DataFrame(history.history)
history_df.loc[0:, ['loss', 'val_loss']].plot()
print(("Minimum Validation Loss: {:0.4f}").format(history_df['val_loss'].min()))이 데이터셋으로 신경망을 학습하려고 하면 일반적으로 실패한다. 만약 되더라도 심각하게 많은 수를 수용하여 과적합이 발생한다.
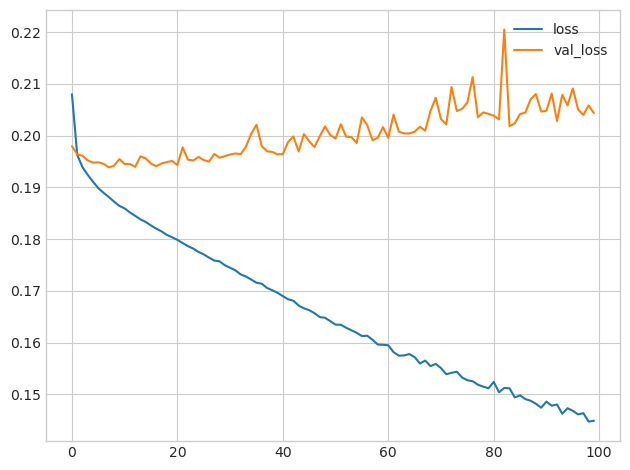
이제 Batch Normalization Layer를 추가한 모델을 학습해본다.
BachNormalization Layer는 각 Dense 앞에 추가한다. ( input_shape은 맨 첫번째 layer 인자로 지정한다 )
# create model
batchnorm_model = keras.Sequential([
layers.BatchNormalization( input_shape=input_shape ),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(512, activation='relu'),
layers.BatchNormalization(),
layers.Dense(1),
])
# compile model
batchnorm_model.compile(
optimizer='sgd', # SGD is more sensitive to differences of scale
loss='mae',
metrics=['mae'],
)
# train model
history = batchnorm_model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=64,
epochs=100,
verbose=0,
)
history_df = pd.DataFrame(history.history)
history_df.loc[0:, ['loss', 'val_loss']].plot()
print(("Minimum Validation Loss: {:0.4f}").format(history_df['val_loss'].min()))
Batch Normalization Layer 추가로 이전 시도보다 크게 개선된 것을 확인할 수 있다.
<관련 포스팅>
[Intro to Deep Learning] A Single Neuron
[Intro to Deep Learning] Deep Neural Networks
[Intro to Deep Learning] MAE, Stochastic Gradient Descent
[Intro to Deep Learning] Underfitting and Overfitting
<참고자료>
https://www.kaggle.com/code/ryanholbrook/dropout-and-batch-normalization

'Data Science > Deep Learning' 카테고리의 다른 글
| PyTorch : NLP Part 1 | Getting Started with Natural Language Processing using PyTorch (0) | 2023.03.17 |
|---|---|
| PyTorch : #5 Mastering Transfer Learning with PyTorch: A Comprehensive Guide (0) | 2023.03.15 |
| [NLP] 자연어 작업 종류 (0) | 2023.03.04 |
| PyTorch : #4 Building Neural Network (0) | 2023.02.25 |
| PyTorch : #3 DataSet and DataLoader (0) | 2023.02.25 |





최근댓글