목차
- 머신러닝이란
- 머신러닝의 분류
- 지도학습 (Supervised Learning)
- 비지도학습 (Unsupervised Learning)
- 강화학습 (Reinforcement Learning)
- 지도학습과 비지도학습 비교
머신러닝이란?
컴퓨터가 스스로 학습할 수 있는 알고리즘이나 기술을 개발하는 분야를 가르킨다.
<머신러닝의 동작>
1. Data Input : 일정량의 이상의 샘플(학습) 데이터를 입력한다.
2. Learning : 입력 받은 데이터를 분석하고 학습한다.
3. Discover(Model) : 일정한 패턴과 규칙을 찾아낸다.
4. Decision & Precdiction : 찾아낸 패턴과 규칙을 이용해서, 의사결과 및 예측 등을 수행한다.
다시 한번 정의하자면,
데이터를 기반으로 패턴을 학습하고, 결과를 예측하는 알고리즘 기법 또는 데이터를 학습하여 의미있는 패턴을 찾아내고 이를 활용하는 일련의 행위라고 할 수 있다.
머신 러닝의 교육 및 예측 단계
ML 프로세스는 주로 학습 과 예측 의 두 단계로 구성된다. 첫째, 훈련 단계에서 ML 알고리즘은 특정 데이터 세트를 입력으로 사용한다. ML 알고리즘은 학습된 모델을 생성하여 입력 데이터에 대한 예측한다. 학습에 사용된 데이터는 학습된 모델이 올바르게 작동하는지 확인하기 위해 예측 단계에서 사용할 수 없다는 점을 중요하다. 모델은 훈련하는 데 이미 사용된 데이터에 대해 신뢰할 수 있는 출력을 생성하지 않기 때문입니다. 따라서 훈련 및 모델 평가를 위해 기존 데이터 세트를 분할하는 것이 좋다.

인공지능
인공지능(AI:Artificial Intelligence) 일반적으로 기계 또는 일반적으로 컴퓨터 프로그램을 통해 인간 행동의 구조를 모방하거나 복제하는 것을 가리킵니다. AI라는 용어는 전문가 시스템, 패턴 분석 시스템 또는 로봇 공학 등 다양한 하위 분야에서 사용됩니다. AI 기반의 시스템은 인간의 행동과 의사 결정 구조를 모방하거나 모델링하기 위해 통계학적 알고리즘, 휴리스틱 절차, 인공 신경망(ANN) 또는 그 밖의 머신러닝 변형 등 다양한 방법을 활용합니다.

딥러닝
머신 러닝의 한 방법으로, 학습 과정 동안 인공 신경망으로서 예시 데이터에서 얻은 일반적인 규칙을 독립적으로 구축(훈련)합니다. 특히 머신 비전 분야에서 신경망은 일반적으로 데이터와 예제 데이터에 대한 사전 정의된 결과와 같은 지도 학습을 통해 학습됩니다.
머신러닝의 분류
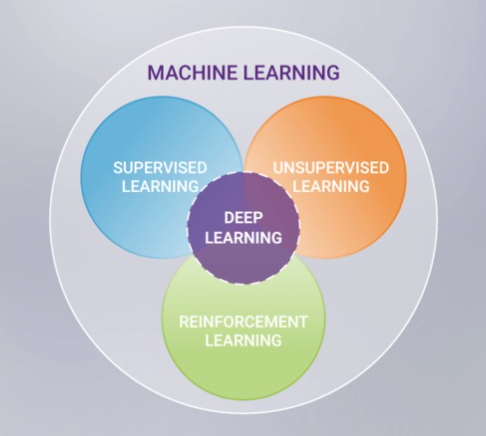
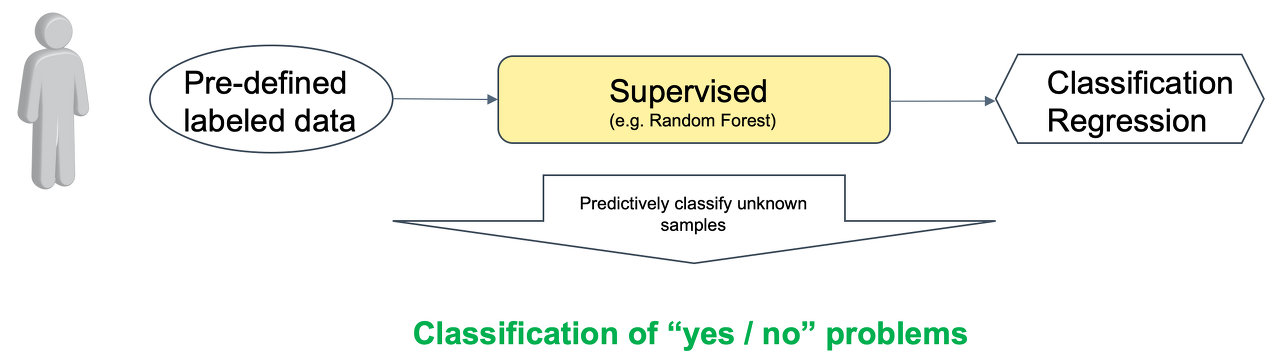
Supervised Learning ( 지도학습 )
답(Label)이 있는 여러 문제를 학습함으로써 미지의 문제에 대한 올바른 답을 예측하고자 하는 방법이다.
예를 들어, 각 사진에 해당 동물을 어떤 동물인지 Label(강아지, 고양이...) 지정하고, 이 데이터를 학습하여 강아지&고양이를 분류하는 모델을 만들어 낸다.

대표적인 모델과 알고리즘
* Classification Model (분류) : KNN(K Nears Neighbor), SVM(Support Vector Machine), Decision Tree
* Predictive Model (예측) : Regression (회귀)
분류 모델은 레이블(Lable)이 달린 학습 데이터로 학습한 후에 새로 입력된 데이터가 어느 그룹에 속하는 지를 찾아내는 방법이다. 분류 모델의 결과값은 언제나 학습했던 데이터의 레이블 중 하나가 된다.
예측 모델은 분류 모델과는 달리 레이블이 달린 학습 데이터를 가지고 특징(feature)과 레이블(label) 사이의 상관 관계를 함수식으로 표현하며, 특정 x값이 주어지면 y 값을 예측값이 구할 수 있다.

지도학습은 모델을 훈련(Training or Learning)하는데 사용할 수 있는 정답이 있는 문제에 적합하다.
Unsupervised Learning (비지도학습)
때로는 레이블(Label)이 깔끔하게 지정된 데이터 세트를 구하기 어렵거나, 답을 모르는 문제가 존재한다. 이럴 때 비지도 학습으로 접근해볼 수 있다.
비지도 학습은 답이 없는 여러 문제를 학습하여 특징을 스스로 파악하여 일정한 패턴을 찾는 방법이다.


비지도학습은 학습 결과에 대한 평가가 어려우며, 데이터 이해 위한 분석 단계에서 유용하게 활용할 수 있다.
<비지도 학습의 기법>
| 군집화 | 거리 기반 군집화 |
– 중심값과의 최소거리 기반 군집 형성 – 군집 수 선정 → 좌표 계산 → 중심값이동(반복) |
| 밀도 기반 군집화 |
– 군집을 이루는 벡터 밀도 기반 군집 형성 – 군집 벡터 수 선정 → 반경 내 군집 → 중심벡터 변경(반복) |
|
| 패턴인식 | 전처리 / 특징 추출 |
– 표본화, 정규화, 노이즈 제거 – 주성분 분석, 데이터 마이닝 |
| 모델 선택 / 인식 |
– Bagging/Boosting, 앙상블 학습 – 혼동 행렬, ROC Curve, AUC, FP Rate |
대표적인 모델과 알고리즘
* Clustering Model ( 군집 )
* Association Model ( 연관 )
* Autoencoder Model
* 패턴 인식
특히, 군집은 가장 많이 사용되는 방법으로 바로 입력된 데이터가 어떤 형태로 서로 그룹을 형성하는지를 파악하는 것이다. 군집화(Clustering)는 레이블이 없는 학습 데이터들의 특징(feature)을 분석하여 서로 동일하거나 유사한 특징을 가진 데이터끼리 그룹화 함으로써 레이블이 없는 학습 데이터를 군집(cluster, 그룹)으로 분류합니다. 그리고 새로운 데이터가 입력되면 지도 학습의 분류 모델처럼 학습한 군집을 가지고 해당 데이터가 어느 군집에 속하는지를 분석하는 것이다.

| 분류 | 알고리즘 | 설명 |
| 데이터 관계 | K-Means | – 임의의 중심점 기준 최소 거리 기반 군집화 – Code-Vector, 유클리드 거리 계산, 노이즈에 민감 |
| DBSCAN | – 반경 내 데이터 벡터 밀도 기반 군집화 – ε, minPts, Core Point, 노이즈에 강함 |
|
| 특징 추출 | Mean Shift | – 임의 영상을 몇 개 영역으로 분할, 군집화 – 컴퓨터 비전, 머신 비전, 영상 분할 |
| 주성분 분석 | – 사물의 주요 특징 분석 및 추출 – 차원 축소, 축 상의 투영으로 표시 |
Reinforcement Learning (강화학습)
지도학습 및 비지도 학습은 학습 데이터가 주어진 상황에서 환경에 변화가 없는 정적인 환경에서 학습을 진행했다면,
강화 학습은 어떤 환경 안에서 정의된 주체(agent)가 현재의 상태(state)를 관찰하여 선택할 수 있는 행동(action)들 중에서 가장 최대의 보상(reward)을 가져다주는지 행동이 무엇인지를 학습하는 것이다.
사람이 지식을 습득하는 방식 중 하나인 시행착오를 겪으며 학습하는 것과 매우 흡사한 기법이다.
대표적인 알고리즘
Markov decision process
강화 학습의 동작
1. Observation : 정의된 주체(agent)가 주어진 환경(environment)의 현재 상태(state)를 관찰(observation)한다.
2. Action : 관찰 결과를 바탕으로 이를 기반으로 행동(action)을 취한다.
3. Reward : 이때 환경의 상태가 변화하면서 정의된 주체는 보상(reward)을 받게 된다.
4. Reinforcement : 정의된 주체(Agent)는 더 나은 보상을 얻을 수 있는 방향(best action)으로 행동을 반복하여 학습한다.

지도 학습과 비지도 학습 비교
| 사용 이유 | – 예측 모델 생성 | – 고차원 데이터 분류 |
| 성능 평가 | – 교차 검증 수행 | – 검증 방법 없음 |
| 입력 정보 | – Labeled Data | – Raw Data |
| 유형 | – 회귀: (x, y)로 f(x)=y파악 – 분류: 그룹별 특징 파악 |
– 군집: 데이터끼리 묶음 – 패턴인식: 여러그룹인식 |
| 알고리즘 | – CNN, RNN, SVM, 의사결정 트리 등 | – K-Means, DBSCAN, 군집(Clustering) 등 |
| 장점 | – 사람이 목표 값에 개입하여 정확도가 높음 | – 목표 값을 정해주지 않아도 되므로 속도 빠름 |
| 단점 | – 시간이 오래 걸리고 학습 데이터 양이 많음 | – 학습 결과로 분류 기준과 군집 예측 불가 |
| 사례 | – 패턴인식, 질병진단 – 주가 예측, 회귀 분석 |
– 스팸필터, 차원 축소 – 데이터마이닝, 지식발굴 |
부록#1) 데이터 마이닝에서의 기법 분류
| 기법 분류 | 데이터마이닝 세부 기법 | 설명/특징 |
| Association (연관) | 지지도 (Support) | 전체 거래 중 항목 X와 항목 Y를 동시에 포함하는 거래의 정도 |
| 신뢰도 (Confidence) | 항목 X를 포함하는 거래 중에서 항목 Y가 포함될 확률이 어느 정도인가를 나타내며 연관성의 정도 | |
| 향상도 (Lift) | 품목Y에 대한 거래중에서 품목X에 대한 거래를 조건부로 하였을때 발생할 확률case의 상관 관계 | |
| Apriori 알고리즘 | 빈발항목 집합 | |
| Sequence (시간) | 시계열성 | 시간적 locality |
| LSTM (Long Short Term Memory) | 시계열적으로 저장여부를 결정가능한 게이트의 사용한 신경망 | |
| 언어모델링/분석 | 시계열적, 확률벡터 사용, 차원의 축소 | |
| Classification (분류) | Decision Tree | 트리형성, Branch제거, Split Criterion, Stopping Rule, Gain Chart, Risk Chart, Test Validation |
| Clustering (군집) | K-means 알고리즘 | 평균값 이용 |
| K-medoids 알고리즘 | 거리기반 | |
| KNN(nearest neighbor) | 베이즈오차율 참조 | |
| 계층적 군집화 | 트리구조 | |
| SOM(Self Organized Map) | 2차원 투영(차원축소) | |
| Characterization (특징) | PCA(Principle Componenet Analysis) | 영향을 미치는 주요 속성, 변수 |
| ICA(Independent Componenet Analysis) | 국부적 특징 도출 | |
| CNN(Convolution Neural Network) | 이미지의 sliding window |
참고자료
TCPSchool - Machine Learning
http://www.tcpschool.com/deep2018/deep2018_machine_learning
Nvidia - 지도 학습, 비지도 학습, 반 지도 학습 및 강화 학습의 차이점은 무엇입니까?
https://blogs.nvidia.com/blog/2018/08/02/supervised-unsupervised-learning/
Reinforcement Learning Coach
https://intellabs.github.io/coach/design/control_flow.html
Synopsys - What is Reinforcement Learning?
https://www.synopsys.com/ai/what-is-reinforcement-learning.html#how-rl-works
Reinforcement Learning, Part 1: A Brief Introduction
Welcome back to my blog for engineers who want to learn AI! In my last post, I talked about how to level up your machine learning career path. Today, I’ll help you continue your journey by introducing Reinforcement Learning.
In addition to defining Reinforcement Learning (RL), this article will give you a simple but essential picture of what it looks like in practical application.
By the end, you will have a basic knowledge of:
- What reinforcement learning is;
- How to frame your task into an RL problem;
- The relationship between RL and supervised/unsupervised learning;
- Using OpenAI Gym to run an RL demo with a simple policy.
How Do We Define Reinforcement Learning?
Reinforcement Learning is a subfield of machine learning that teaches an agent how to choose an action from its action space, within a particular environment, in order to maximize rewards over time.
Reinforcement Learning has four essential elements:
- Agent. The program you train, with the aim of doing a job you specify.
- Environment. The world, real or virtual, in which the agent performs actions.
- Action. A move made by the agent, which causes a status change in the environment.
- Rewards. The evaluation of an action, which can be positive or negative.
Real-World Examples Of Modeling A Reinforcement Learning Task
The first step in modeling a Reinforcement Learning task is determining what the 4 elements are, as defined above. Once each element is defined, you’re ready to map your task to them.
Here are some examples to help you develop your RL intuition.
Determining the Placement of Ads on a Web Page
Agent: The program making decisions on how many ads are appropriate for a page.
Environment: The web page.
Action: One of three: (1) putting another ad on the page; (2) dropping an ad from the page; (3) neither adding nor removing.
Reward: Positive when revenue increases; negative when revenue drops.
In this scenario, the agent observes the environment and gets its current status. The status can be how many ads there are on the web page and whether or not there is room for more.
The agent then chooses which of the three actions to take at each step. if programmed to get positive rewards whenever the revenue increase, and negative rewards whenever revenue falls, it can develop its effective policy.
Creating A Personalized Learning System
Agent: The program that decides what to show next in an online learning catalog.
Environment: The learning system.
Action: Playing a new class video and an advertisement.
Reward: Positive if the user chooses to click the class video presented; greater positive reward if the user chooses to click the advertisement; negative if the user goes away.
This program can make a personalized class system more valuable. The user can benefit from more effective learning and the system can benefit through more effective advertising.
Controlling A Walking Robot
Agent: The program controlling a walking robot.
Environment: The real world.
Action: One out of four moves (1) forward; (2) backward; (3) left; and (4) right.
Reward: Positive when it approaches the target destination; negative when it wastes time, goes in the wrong direction or falls down.
In this final example, a robot can teach itself to move more effectively by adapting its policy based on the rewards it receives.
Supervised, Unsupervised, and Reinforcement Learning: What are the Differences?
Difference #1: Static Vs.Dynamic
The goal of supervised and unsupervised learning is to search for and learn about patterns in training data, which is quite static. RL, on the other hand, is about developing a policy that tells an agent which action to choose at each step — making it more dynamic.
Difference #2: No Explicit Right Answer
In supervised learning, the right answer is given by the training data. In Reinforcement Learning, the right answer is not explicitly given: instead, the agent needs to learn by trial and error. The only reference is the reward it gets after taking an action, which tells the agent when it is making progress or when it has failed.
Difference #3: RL Requires Exploration
A Reinforcement Learning agent needs to find the right balance between exploring the environment, looking for new ways to get rewards, and exploiting the reward sources it has already discovered. In contrast, supervised and unsupervised learning systems take the answer directly from training data without having to explore other answers.
Difference #4: RL is a Multiple-Decision Process
Reinforcement Learning is a multiple-decision process: it forms a decision-making chain through the time required to finish a specific job. Conversely, supervised learning is a single-decision process: one instance, one prediction.
An Introduction to OpenAI Gym
OpenAI Gym is a toolkit for developing and comparing reinforcement learning algorithms. It supports teaching agents in everything from walking to playing games like Pong or Pinball.
OpenAI Gym gives us game environments in which our programs can take actions. Each environment has an initial status. After your agent takes an action, the status is updated.
When your agent observes the change, it uses the new status together with its policy to decide what move to make next. The policy is key: it is the essential element for your program to keep working on. The better the policy your agent learns, the better the performance you get out of it.
Here is a demo of the game CartPole from OpenAI. We can see the policy on the sixth line: the agent may take a random action from its action space.
import gym
env = gym.make("CartPole-v1")
observation = env.reset()
for _ in range(1000):
env.render()
action = env.action_space.sample() # your agent here (this takes random actions)
observation, reward, done, info = env.step(action)
if done:
observation = env.reset()
env.close()The 2nd line creates a CartPole environment.
The 3rd line initializes the status parameters.
The 5th line shows the game.
The 6th line prompts an action with a policy that is ‘random’.
On the 7th line, the action is taken and the environment gives four returns:
- Observation: Parameters of the game status. Different games return different parameters. In CartPole, there are four in total. The second parameter is the angle of the pole.
- Reward: The score you get after taking this action.
- Done: Game over or not over.
- Info: Extra debug information. It could be cheating.
The 8th line means if the game is done; restart it.
Reinforcement Learning Demo
The policy can be programmed in any way you like. It can be based on if-else rules or a neural network. Here is a little simple demo, with the simplest policy for the CartPole game.
import gym
def policy(observation):
angle = observation[2]
if angle < 0:
return 0
else:
return 1env = gym.make("CartPole-v1")
observation = env.reset()
for _ in range(1000):
env.render()
action = policy(observation)
observation, reward, done, info = env.step(action)
if done:
observation = env.reset()
env.close()Of course, the policy function content can be replaced by a neural network, with observation parameters as input and an action as output.
Conclusion:
- Reinforcement Learning is a subfield of machine learning, parallel to but differing from supervised/unsupervised learning in several ways.
- Because it requires simulated data and environment, it is harder to apply to practical business situations.
- However, its learning process is natural to sequential decision-making scenarios, making RL technology undeniably promising.
There are currently two principal methods often used in RL: probability-based Policy Gradients and value-based Q-learning.
I’ve covered many of these topics already, in the following posts:
Part 1: A Brief Introduction to RL
Part 2: Introducing the Markov Process
Part 3: Markov Decision Process (MDP)
Part 4: Optimal Policy Search with MDP
Part 5: Monte-Carlo and Temporal-Difference Learning
Part 7: A Brief Introduction to Deep Q Networks
so stay tuned!
'Data Science > Machine Learning' 카테고리의 다른 글
| 비지도학습 : DBSCAN (0) | 2022.01.25 |
|---|---|
| 머신러닝 분류 : 강화학습 (0) | 2022.01.25 |
| [머신러닝] 학습한 모델의 저장과 로딩 (0) | 2022.01.21 |
| Real-time Object Detection algorism : YOLO v3 (0) | 2021.09.08 |
| Python ML : numpy (0) | 2021.02.16 |





최근댓글